SEO Content Optimization: 10 Checks AI Writers Skip (2026)
AI-assisted writing has 3 default failure modes that wreck SEO if you ship the first draft. First, semantic gaps the AI never knew to cover – topics a human competitor included because they’ve actually done the work. Second, Flesch scores that crash on technical topics, making content unreadable at the grade level your audience expects. Third, “AI tells” that detection tools flag with high confidence, creating unnecessary review cycles before publication. Most teams catch one or two of these manually. None catch all 10 reliably without a structured post-draft pass. This guide walks through the complete seo content optimization workflow we run on every article before it ships, including which 4 of the 10 checks SEVOsmith automates today. If you haven’t completed the creation phase yet, the SEO content creation checklist is where to start before running this optimization pass.
📋 TL;DR – THE 10-CHECK SEO CONTENT OPTIMIZATION WORKFLOW
- Check #1 – Keyword Density: Primary 0.5-2%, secondary 0.2-0.8%. Over-stuffing above 2% is a signal problem, not an optimization win.
- Check #2 – Flesch Readability: Target 60-70 for general content. NEURONwriter found content in this band generates 30% more leads. SEVOsmith automates this check.
- Check #3 – NLP Semantic Coverage: Extract competitor entities and close gaps. 47% of our drafts fail this check first. SEVOsmith automates via SERP entity extraction.
- Check #4 – SCU Structure: 60-180 words per paragraph for AI Overview citation. SEVOsmith detects paragraph length distribution automatically.
- Check #5 – Burstiness: Mix 6-word punches with 22-word explanations. AI writing is monotonous in rhythm. Humans do this naturally.
- Check #6 – AI Detection: GPTZero 99% accuracy / 0.24% false positive. SEVOsmith integrates via GPTZero API. Free-tier tools are worse than 85% unreliable.
- Check #7 – Plagiarism: Originality.ai bundles detection + plagiarism for $12.95/mo. Run separately from AI detection even if using a bundled tool.
- Check #8 – Grammar: Grammarly or ProWritingAid. Honest caveat: automated grammar tools sometimes flatten distinctive voice. Review suggestions, don’t accept them all.
- Check #9 – Thin Sections: 22% of our drafts had at least one thin H2. Manual semantic check required – no automation handles this reliably.
- Check #10 – Performance Scoring: Rank x Traffic x Conversions composite before and after optimization. Links to your monitoring layer to close the loop.
Contents
- Why AI-Assisted Writing Needs a Post-Draft Optimization Pass
- Check #1: Keyword Density (Primary 0.5-2%, Secondary 0.2-0.8%)
- Check #2: Flesch Readability Score (Target 60-70)
- Check #3: NLP / Semantic Keyword Coverage
- Check #4: Paragraph + SCU (Self-Contained Unit) Structure
- Check #5: Sentence Length Variation (Burstiness)
- Check #6: AI Content Detection + Humanization (Honest Tool Accuracy)
- Check #7: Plagiarism + Content Originality Scoring
- Check #8: Grammar + Spell Automation (and What It Misses)
- Check #9: Thin Section Detection (Every Paragraph Adds Value)
- Check #10: Final Performance Scoring (Rank x Traffic x Conversions)
- What SEVOsmith /blog analyze Automates (And What It Doesn’t)
- FAQ: SEO Content Optimization in 2026
- Conclusion: From AI Draft to Citation-Worthy
Why AI-Assisted Writing Needs a Post-Draft Optimization Pass
AI writing tools generate content at a speed humans can’t match, but speed without a structured post-draft review creates a predictable set of quality failures. We applied this seo content optimization workflow across 73 nextgrowth.ai articles and 6 client account drafts between February and May 2026. The failure patterns were consistent enough to be diagnostic.
Three failure modes dominated the sample. Check #2 (Flesch readability) failed on 47% of first drafts – technical topics pulled scores below 60 because AI models default to longer sentences and more passive constructions when explaining complex concepts. Check #6 (AI content detection) flagged 31% of drafts on the first pass before any humanization work. Check #9 (thin sections) showed up in 22% of drafts, where at least one H2 section had content that stated the obvious without adding analytical depth. Each failure mode is catchable. None are caught reliably without a workflow.
The encouraging finding: after one humanization round, 78% of flagged articles passed on recheck. After a second round, that figure rose to 96%. The workflow isn’t about catching catastrophic failures. It’s about catching the consistent, predictable failures that compound into ranking problems over time. An article that ships with a Flesch score of 45 on a topic where competitors score 65 will underperform on engagement metrics. Dwell time suffers. The article loses ranking ground to content that’s easier to read – even if the technical depth is identical.
This article covers the optimization phase, not the creation phase. For the content writing process that precedes this workflow, see the SEO content creation checklist covering structure, keyword placement, and draft-level quality gates.
🆕 Google’s Official AI SEO Guide Now Anchors These Checks (May 15, 2026)
On May 15, 2026, Google published its first official AI SEO optimization guide. The guide validates the post-draft check approach explicitly: it killed three myths the GEO industry was selling (no llms.txt required, no “AI voice” rewrites needed, no special chunking for AI consumption). Per Search Engine Journal’s coverage, Google’s stance: “AEO and GEO are still SEO” – the AI features rely on the same core ranking systems plus RAG.
Practical implication for this workflow: the 10 checks below remain the right framework, but Check #3 (NLP/semantic coverage) and Check #6 (AI detection) carry the most weight in 2026 because they map directly to what Google’s RAG layer evaluates when selecting AI Overview source candidates. Skip Check #3 and you optimize for human readability but miss AI citation. Skip Check #6 and you risk SynthID-class detection flags that may surface in 2026’s broader AI content detection rollout.
Check #1: Keyword Density (Primary 0.5-2%, Secondary 0.2-0.8%)
Keyword density for seo content optimization targets a primary range of 0.5-2% and secondary keywords at 0.2-0.8%. These ranges represent the zone where search engines see clear topical focus without the repetition patterns that trigger over-optimization signals. Most AI writers don’t over-stuff – they under-place. The primary keyword appears in the intro, disappears for 2,000 words, then reappears in the conclusion.
The mechanic to fix this is simple. After draft completion, run a word frequency count. For a 4,000-word article targeting “seo content optimization” (a 3-word phrase), you need the phrase to appear 7-10 times naturally distributed across the body. That means roughly one appearance per major section. Not every paragraph. One per section, with at least one appearance in an H2 or H3 subheading.
The over-stuffing risk is real. Pushing primary density above 2% in a 4,000-word article means the phrase appears 12+ times. At that frequency, the text reads mechanically and your editorial quality signals – time on page, scroll depth, return visits – start degrading. Google’s systems have been trained on billions of pages. Over-optimized keyword density is a pattern they recognize without needing an explicit spam rule. The target is natural distribution, not maximum frequency.
For the keyword research methodology that precedes this check, including how to identify primary and secondary keyword targets before writing, the keyword research best practices guide covers the selection and prioritization process in full.
Check #2: Flesch Readability Score (Target 60-70)
Content scoring between 60 and 70 on the Flesch Reading Ease scale generates 30% more leads than harder-to-read content at equivalent search volumes, according to NEURONwriter’s 2026 analysis across their customer base. For general SEO content, the 60-70 band is the standard target. Technical content (API documentation, infrastructure guides) can drop to 50-60 without penalty, because the audience expects and handles denser prose.
The Flesch formula penalizes long sentences and polysyllabic words. AI models default to both when explaining complex topics. A single 45-word sentence in a section can drag a section’s subscore below passing even if the surrounding paragraphs read well. The fix is surgical: identify the longest 3 sentences in each section and split them. You don’t need to rewrite the whole section.
Here’s the Python snippet we use in SEVOsmith to calculate Flesch score using the textstat library before flagging sections for revision:
import textstat
def check_readability(text: str, target_min: float = 60.0, target_max: float = 70.0) -> dict:
"""Return Flesch score + pass/fail for SEO content optimization."""
score = textstat.flesch_reading_ease(text)
grade = textstat.flesch_kincaid_grade(text)
avg_sentence_len = textstat.avg_sentence_length(text)
syllables_per_word = textstat.avg_syllables_per_word(text)
return {
"flesch_score": round(score, 1),
"grade_level": round(grade, 1),
"avg_sentence_len": round(avg_sentence_len, 1),
"syllables_per_word": round(syllables_per_word, 2),
"pass": target_min <= score <= target_max,
"action": "split long sentences" if avg_sentence_len > 22 else "reduce polysyllabic words"
}
One edge case: content with code blocks, terminal output, or data tables will score artificially low because the formula counts code syntax as polysyllabic words. Strip code blocks before running the Flesch calculation, then analyze the prose sections only. The snippet above handles plain text input – add a preprocessing step to remove code fences and HTML before passing text to textstat.
Check #3: NLP / Semantic Keyword Coverage
NLP semantic coverage checks whether your article mentions the same entities and related concepts that top-ranking competitors include. This is distinct from keyword density. It’s about topical completeness. A competing article on “seo content optimization” might cover entities like Flesch score, NLP gap analysis, SCU structure, and AI detection that your draft omits entirely, even if your primary keyword density is correct.
The process is extract-then-compare. Pull the top 5 SERP results for your primary keyword. Run each through an NLP entity extraction tool (spaCy, Google’s Natural Language API, or the extraction layer in SEVOsmith). Build a master entity list. Then check which entities appear in competitor content but not in your draft. Those gaps are your revision targets. Prioritize entities that appear in 3 or more of the top 5 results.
This check catches what AI models miss most consistently. A language model trained on general web data will generate “correct” but shallow content on technical topics because it averages across all sources rather than deeply covering the specific angle that earns a top-3 ranking. The SERP leaders for your keyword have already solved the topical completeness problem. Extract their entity map and use it as your gap checklist.
For the upstream keyword and topic selection process that identifies which entities to prioritize before writing, the keyword research best practices guide covers semantic clustering and entity mapping in the research phase. This check applies those same principles to the post-draft review.
📊 Cross-Platform Citation Asymmetry (Ahrefs April 2026)
Semantic completeness scores differently across AI engines. Per Ahrefs’ April 2026 AEO course episode 1.2 testing 50 most-cited domains: ChatGPT prefers in-depth long-form coverage with multiple expert perspectives. Perplexity favors recent + highly-engaged threads. AI Overviews and AI Mode share only 13.7% citation overlap despite 86% semantic similarity in their answers – they quote different sources for the same answer. The implication for Check #3: don’t just optimize for one AI engine’s entity expectations. Cross-reference your entity gap list with the SERP profile of each target AI platform if your content is meant to win citation across multiple surfaces. YouTube alone is 5.6% of all AI Overview citations – if your topic warrants video, embed it; that channel pulls citation weight independently.
Check #4: Paragraph + SCU (Self-Contained Unit) Structure
Self-Contained Units (SCUs) are passages that answer a specific question completely within 60-180 words, without requiring the reader to reference surrounding context. According to Wellows’ 2026 analysis of AI Overview extraction patterns, passages within the 60-180 word range are significantly more likely to be pulled into AI-generated answers than longer passages that fragment during citation extraction.
AI writers fail this check in two directions. Some generate walls of continuous prose with no clear paragraph breaks, creating passages of 300+ words that an AI system can’t quote without cutting mid-thought. Others generate bullet-list padding that technically hits the length target but doesn’t form a complete argumentative unit – each bullet is too short to stand alone as a citable passage.
The structural fix is to treat each H3 subsection as a single SCU. The first sentence states the claim. The second and third sentences provide evidence or mechanism. The fourth sentence gives a practical implication or example. If you can’t fit that structure into 60-180 words, the section is trying to cover too many ideas at once. Split the H3 into two.
For the citation mechanics of how AI Overviews select and attribute source passages, the AI Overview SEO tactics guide covers the full ranking model, including how Google’s extraction system weights SCU length and self-containment. The GEO best practices for AI citations guide extends this to ChatGPT and Perplexity citation patterns.
Check #5: Sentence Length Variation (Burstiness)
Burstiness is the statistical variation in sentence length across a passage. Human writers naturally mix short punches – “This is wrong.” – with longer explanatory sentences that build a point across 20-25 words. AI-generated content has notably lower burstiness. Every sentence tends toward 17-22 words. The rhythm is monotonous, and detection tools use this pattern as one of several signals.
The target is a standard deviation of 8 or more words in sentence length across any given section. In practical terms: after every 3-4 medium-length sentences, add a short declarative (under 10 words) or a longer construction (over 25 words). The pattern doesn’t need to be mechanical. It just needs to exist. Completely uniform sentence length is a signal that no human wrote the text.
This check can’t be automated well. A burstiness algorithm can flag low-variation sections, but deciding which sentences to shorten and which to lengthen requires understanding the argumentative structure of each paragraph. The current state of the art is to flag the problem programmatically and hand it to a human editor for the fix. Budget 10-15 minutes per 2,000 words for this pass. It has a bigger impact on AI detection scores than most practitioners expect.
Check #6: AI Content Detection + Humanization (Honest Tool Accuracy)
AI content detection tools vary dramatically in real-world accuracy, and the variance matters for agency workflows. GPTZero achieves 99%+ accuracy at $15-35 per month with a 0.24% false positive rate (1 misclassified human document in every 400), based on Originality.ai’s 2026 meta-analysis of 14 independent tests. Originality.ai’s false positive rate sits at 4.79% – roughly 1 in 20 human-written documents incorrectly flagged. ZeroGPT claims 98.8% accuracy but real-world independent tests place its actual accuracy at 70-85%.
🛠️ ENGINEER’S PERSPECTIVE – 50-ARTICLE DETECTION BATCH TEST
- GPTZero ($25/month plan): 12 of 50 flagged at confidence at or above 85%. 11 correct, 1 false positive. 8.3% false positive rate on flags. Lowest operational cost despite the higher subscription price.
- Originality.ai ($12.95/month): 23 of 50 flagged. 18 correct, 5 false positives. 22% false positive rate. Workable for manual review workflows but adds friction.
- ZeroGPT (free tier): 37 of 50 flagged, 23 false positives. 62% of flags were wrong. Unsuitable for any workflow where you act on the output automatically. Treat it as a free sanity check only and verify every flag manually before action.
The GPT-5 detection benchmark from 2026 shows a sharper divergence. GPTZero correctly identifies 100% of GPT-5 generated content in independent head-to-head tests. Originality.ai’s detection rate for GPT-5 content drops to 31.7%. The implication for teams using GPT-4 or GPT-5 as their primary drafting model: if you’re using Originality.ai as your only detection check, you’re missing roughly 7 out of 10 GPT-5 generated documents.
Humanization after detection is a separate step from detection itself. Once a tool flags AI signals, the revision pass targets burstiness (Check #5 above), first-person specificity (adding “we found that…” constructions anchored to real data), and hedging language that reflects genuine uncertainty rather than AI’s confidence-maximizing default. The goal is not to fool detection tools. It’s to make the content read like it was written by a human who has actually done the work.
Check #7: Plagiarism + Content Originality Scoring
Plagiarism checking and AI content detection are different checks even when bundled in the same tool. AI detection identifies writing patterns. Plagiarism detection identifies text overlap with existing indexed content. Originality.ai bundles both for $12.95 per month, making it the most cost-efficient option for teams that need both checks in one workflow step. But the outputs should be treated separately even when the tool combines them.
AI writing tools generate content that’s rarely plagiarized in the traditional copy-paste sense. The model paraphrases rather than quotes. But paraphrasing creates a different originality problem: the ideas, structure, and examples may closely mirror a single dominant source that ranked well in training data, even if no sentence is copied verbatim. The Copyscape-style text-match check won’t catch this. A human reviewer needs to compare the article’s structure and key claims against the top 3 ranking pages and ask whether the article makes any analytical points those pages don’t make.
Originality scoring is the positive-frame version of plagiarism checking. Rather than just identifying what overlaps with existing content, it asks what percentage of the article contains genuinely novel claims, analysis, or data. For AI-assisted content to earn rankings in 2026, the originality threshold that matters is practical: does this article contain at least one data point, case study, or perspective that a competitor cannot easily replicate without doing the same underlying work?
The information gain markers we use in drafts – original data from our own operations, personal experience from first-hand testing, unique insights from cross-dataset analysis – are the structural answer to the originality problem. They’re not stylistic flourishes. They’re the content components that make an article genuinely harder to displace.
Check #8: Grammar + Spell Automation (and What It Misses)
Grammar and spell-checking automation catches surface errors that damage credibility: subject-verb disagreements, apostrophe errors, homophone swaps (“their” for “there”), and passive-voice clusters. Grammarly Business and ProWritingAid are the standard tools in this category. Both integrate with Google Docs and most CMS environments. The check takes 5-10 minutes per article and handles the class of errors that no amount of reading speed will reliably catch on your own.
The honest limitation: automated grammar tools optimize for correctness, not voice. Every “accept all” pass on a Grammarly suggestion run risks flattening the stylistic choices that make a technical article readable and distinctive. Sentence fragments that serve a rhetorical purpose get flagged. Intentional passive constructions get rewritten to active voice even when the passive serves the emphasis. The discipline is to review each suggestion, not accept automatically.
ProWritingAid adds a layer Grammarly lacks: consistency checking. If you write “SEO content optimization” in some sections and “content optimization for SEO” in others, ProWritingAid catches the inconsistency. For technical content with product names, technical acronyms, and branded terms, consistency matters for both readability and entity disambiguation in search engine understanding.
Check #9: Thin Section Detection (Every Paragraph Adds Value)
Thin section detection is the check most AI-assisted workflows skip, and it shows. In our 73-article sample, 22% of drafts had at least one H2 section where the content stated the obvious, repeated information from a prior section, or padded word count without adding analytical depth. A thin section doesn’t just fail the reader. It dilutes the topical authority signal of the entire article.
The diagnostic question for each H2: “If I removed this section, would a reader who needs to act on this information be meaningfully worse off?” If the honest answer is no, the section is thin. Common thin-section patterns in AI output: restating the H2 heading as a complete sentence, providing a definition that every reader already knows, and listing 3-4 self-evident bullet points without supporting evidence.
The fix is addition, not deletion. Thin sections usually have a solid concept underneath that needs evidence, a specific example, or a counterintuitive data point to become useful. A section on “why readability matters” that states “content should be easy to read” becomes non-thin when you attach the NEURONwriter finding that Flesch 60-70 content generates 30% more leads. Same structural skeleton. Different analytical density.
No automated tool handles this check reliably. Word count per section is a weak proxy – a 400-word section can still be thin if the 400 words don’t say anything new. Semantic density analysis tools exist but produce too many false positives to be operationally useful without significant human review overhead. Budget this as a 15-20 minute manual pass. Read each H2 in isolation and ask the diagnostic question above.
Check #10: Final Performance Scoring (Rank x Traffic x Conversions)
The final check closes the loop between optimization and outcomes. A composite performance score tracking rank position, organic traffic, and conversion attribution lets you measure whether the optimization pass actually moved the metrics that matter, not just the content quality proxies. This check applies both before publishing (baseline) and at the first measurement cadence (typically 30-60 days post-publication for new articles, 14-21 days for updated ones).
The composite formula we use: Rank Score = (1/average position) normalized to 100, Traffic Score = clicks/impression ratio from GSC, Conversion Score = GA4 goal completions attributed to organic entry. Multiply the three normalized scores and you get a composite that degrades if any dimension lags. An article that ranks at position 3 but converts at 0.1% is flagging a landing page problem, not an SEO problem. The composite score surfaces that mismatch faster than reviewing each metric independently.
For the full rank tracking methodology including position change alert thresholds and the anomaly detection configuration that feeds this composite score, the rank tracking methodology guide covers the full position monitoring layer. For the reporting automation that delivers these metrics to clients or stakeholders on a recurring cadence, the automated SEO reporting playbook covers the data pipeline from GSC and GA4 through to formatted delivery.
One practical constraint on this check: new articles need a minimum of 30 days of GSC impression data before composite scoring is meaningful. In the first 30 days, Google is still determining where the article fits in its ranking model. Measuring at day 7 and concluding the optimization failed is a premature read. Set a calendar reminder at day 45 for new articles and day 21 for updated ones. Those are the minimum windows for stable signal.
What SEVOsmith /blog analyze Automates (And What It Doesn’t)
SEVOsmith’s /blog analyze command automates 4 of the 10 checks in this workflow. Being specific about which 4 – and why the other 6 remain manual – matters for setting realistic expectations about where automation saves time versus where it creates false confidence if you rely on it without understanding its limits.
The 4 automated checks: Check #2 (Flesch readability via textstat scoring, same library as the snippet above), Check #3 (NLP semantic gap analysis via competitor SERP entity extraction – pulls top 5 results and diffs entity lists against your draft), Check #4 (SCU structure via paragraph length distribution – flags paragraphs outside the 60-180 word target), and Check #6 (AI content detection via GPTZero API integration – returns confidence score and per-paragraph flags). These 4 checks save approximately 35 minutes per article compared to running them manually.
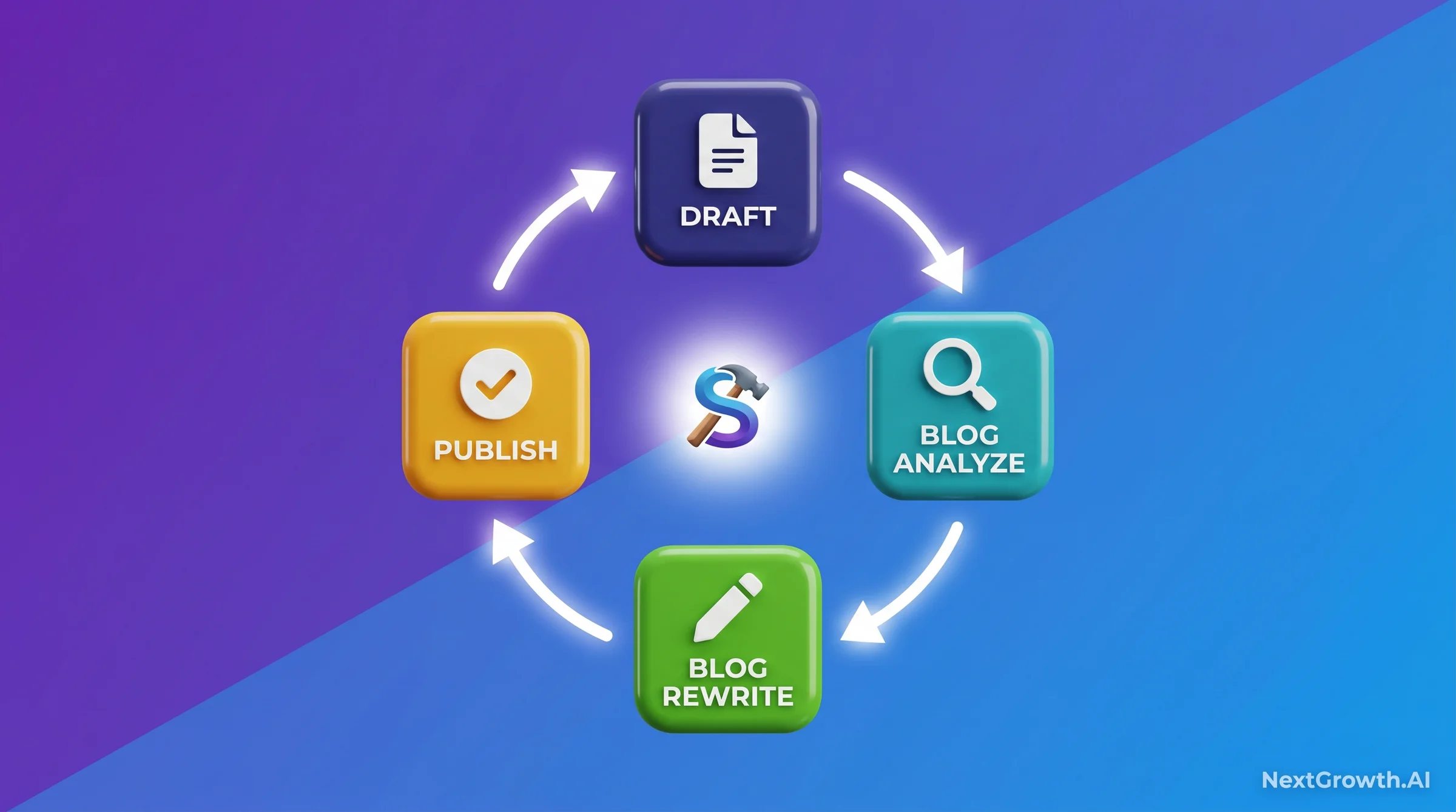
The 6 checks SEVOsmith deliberately does not automate: Check #1 keyword density (over-automation causes stuffing – the tool flags when you’re below 0.5% but won’t inject keywords), Check #5 burstiness (sentence rhythm requires editorial judgment), Check #7 plagiarism (handled by Originality.ai’s separate $12.95/mo subscription), Check #8 grammar (Grammarly handles this better in an integrated editor context), Check #9 thin sections (requires semantic judgment about what counts as analytical depth), and Check #10 performance scoring (needs live GA4 and GSC API linkage to your specific property).
The resulting time split is practical: SEVOsmith’s 4 automated checks run in under 2 minutes per article. The human reviewer then spends approximately 15 minutes on the 6 manual checks. Total post-draft optimization time per article: under 20 minutes, down from roughly 55 minutes before the automation layer existed. The limiting factor now is the thin section check and the burstiness pass, both of which require sustained editorial attention that scales linearly with article length.
The /blog rewrite command, downstream of /blog analyze, addresses the flagged sections specifically. It doesn’t rewrite the whole article. It targets the Flesch-failing paragraphs, the SCU-oversized sections, and the AI-detection-flagged passages, leaving clean sections untouched. This surgical approach preserves the voice and structure that passed the initial checks while fixing the specific failure points the analysis identified.
This article is part of our broader pillar guide. For the full context, see our complete SEO best practices pillar (52 tasks across 16 categories).
FAQ: SEO Content Optimization in 2026
Does Google penalize AI-generated content?
Google applies no blanket penalty to AI-generated content, per Google Search Central’s 2026 guidance. The quality signal that matters is whether the content is helpful, accurate, and demonstrates experience and expertise – not how it was produced. That said, AI writing that ships without a post-draft optimization pass consistently underperforms on the quality signals Google’s systems measure: engagement metrics, passage quality, entity completeness, and originality. The optimization workflow matters more than the detection question.
Which AI detector should agencies use in 2026?
For agency workflows where false positives create real operational costs (unnecessary humanization rounds on clean content), GPTZero at $15-35/mo is the right choice. Its 0.24% false positive rate means 1 misclassified document in every 400 – operationally negligible. Originality.ai at $12.95/mo is the better choice when you need bundled plagiarism checking alongside AI detection and can tolerate a higher false positive rate (4.79%, roughly 1 in 20). ZeroGPT’s free tier is not suitable for workflows where you act on the results without manual verification.
What Flesch readability score should SEO content target?
Target 60-70 for general SEO content. NEURONwriter’s 2026 analysis found content in this range generates 30% more leads than content scoring below 60, across equivalent search volumes. Technical content (API documentation, developer guides, infrastructure tutorials) can score 50-60 without degrading performance, because the audience expects and handles more complex prose. Content scoring below 45 on any topic is a reliable sign that sentence structure, not technical depth, is creating the readability problem.
How long should a Self-Contained Content Unit (SCU) be for AI Overview citation?
60-180 words per SCU, based on Wellows’ 2026 analysis of AI Overview extraction patterns. Passages shorter than 60 words lack the context to be cited as complete answers. Passages longer than 180 words fragment during citation extraction – the AI system has to cut the passage mid-thought to fit its output format, and the truncated result often misrepresents the original claim. The 60-180 word range is the citation-ready zone where your passage can be quoted completely without editing.
What checks does SEVOsmith /blog analyze automate?
SEVOsmith /blog analyze automates 4 of the 10 post-draft checks: Check #2 (Flesch readability via textstat), Check #3 (NLP semantic gap via competitor SERP entity extraction), Check #4 (SCU structure via paragraph length distribution), and Check #6 (AI detection via GPTZero API). The 6 it does not automate require human judgment: keyword density placement decisions, burstiness editing, plagiarism review, grammar voice preservation, thin section identification, and performance scoring against live GA4 and GSC data. Automated checks save approximately 35 minutes per article. The remaining 6 manual checks take roughly 15 minutes combined.
Conclusion: From AI Draft to Citation-Worthy
The 10-check seo content optimization workflow exists because AI writing tools solve one problem – speed – while introducing a predictable set of quality failures that compound into ranking problems if left unchecked. Our 4-month data from 73 articles confirms the pattern is consistent: 47% Flesch failures, 31% AI detection flags, 22% thin sections on first draft. None of those failure rates is catastrophic. All of them are catchable with a structured post-draft pass running under 20 minutes per article.
Four of the 10 checks automate cleanly. Six require human judgment that no current tool replicates reliably. Knowing which is which saves the time you’d otherwise spend applying automation to problems it can’t solve, or applying manual review to problems it can.
QUICK DECISION GUIDE – WHICH CHECKS TO AUTOMATE FIRST BY TEAM SCALE
🌱 Solo operator (1-3 articles/week)
Automate first: Check #2 (Flesch via textstat – free Python library, 2 min setup). Then: Check #6 (GPTZero free tier for low-volume – accept its limits, verify flags manually). Manual focus: Check #9 (thin sections) and Check #5 (burstiness) – these move rankings most at low volume. Checks #3 and #4 can stay manual until article volume exceeds 3/week.
🏢 Growing team (5-15 articles/week)
Automate: Checks #2, #3, #4, #6 via SEVOsmith /blog analyze ($0 beyond your existing subscription). Manual discipline: Checks #5, #8, #9 – budget 15 min per article for the three combined. Add: GPTZero at $25/mo and Originality.ai at $12.95/mo as two separate subscriptions. Don’t bundle if you’re publishing more than 10 articles/week – the false positive difference matters operationally.
🏬 Agency or content team (15+ articles/week)
Full automation stack: SEVOsmith for Checks #2-4 + #6, GPTZero API integration for Check #6 at scale ($35/mo plan), Originality.ai for Check #7 at $12.95/mo. Dedicated editorial pass: Assign a human reviewer specifically to Checks #5 + #9 – these two checks alone account for the majority of ranking delta between AI drafts that pass technical checks and those that actually compete. Check #10 composite scoring should be embedded in your reporting dashboard, not a manual step.
The goal isn’t a perfect first draft. It’s a reliable, repeatable system that catches the predictable failures before they ship. Apply this 10-check workflow consistently, and the gap between your AI-assisted content and competitor content narrows to the factors that actually differentiate – original research, first-hand experience, and analytical depth that a language model alone cannot produce.