n8n Error Handling: Complete Guide to Workflow Resilience (2026)
We run over 200 n8n workflows in production at NextGrowth.ai. SEO pipelines, lead enrichment, content publishing, monitoring alerts. When one of those workflows fails silently at 2 AM, nobody knows until a client asks why their report is empty.
That happened to us in early 2025. A DataForSEO API workflow had been failing for 11 days. No alert. No log entry. Just a quietly broken pipeline and a very confused client. That incident cost us a week of manual data recovery and one awkward conversation.
So we rebuilt our entire error handling architecture from scratch. Three layers: node-level retries for transient failures, a global error trigger that catches everything else, and centralized logging that gives us a single dashboard for every failure across every workflow. After deploying this system, our mean time to detect failures dropped from days to under 90 seconds. All performance metrics in this guide come from our internal n8n execution logs across 200+ workflows on self-hosted instances, January through December 2025.
This guide shares the exact setup we use. You’ll get real JSON workflow templates you can import directly, JavaScript code for the Function nodes, and the specific configuration decisions we made after testing alternatives. If you’re new to n8n and how it works, start there first.
TL;DR: n8n error handling works best as a three-layer system: node-level retries catch transient failures (API timeouts, rate limits), a global Error Trigger workflow catches everything that slips through, and centralized logging to Google Sheets or PostgreSQL gives you visibility across all workflows. We’ve run this pattern across 200+ production workflows since early 2025 with a 99.4% error detection rate.
All templates and code in this guide were tested on n8n v1.30+ with Docker Compose. They work on both Community Edition and Cloud.
Contents
- What Is n8n Error Handling and Why Does It Matter?
- What Are the Three Types of n8n Error Handling?
- How Do You Set Up a Global Error Trigger Workflow?
- How Do You Build Smart Retry Logic with Exponential Backoff?
- How Do You Build Centralized Error Logging?
- How Do You Handle API Errors and HTTP Failures?
- How Do You Prevent Bad Data from Breaking Workflows?
- How Do You Monitor n8n Error Handling at Scale?
- What Are the Most Common n8n Error Handling Mistakes?
- Frequently Asked Questions
- How do you enable Retry on Fail for a specific node in n8n?
- What is the difference between the Error Trigger node and the Error Workflow setting?
- Can you use n8n error handling with queue mode and multiple workers?
- How do you prevent alert fatigue from n8n error notifications?
- What happens if the Error Workflow itself fails?
- Start Building Your n8n Error Handling System Today
What Is n8n Error Handling and Why Does It Matter?
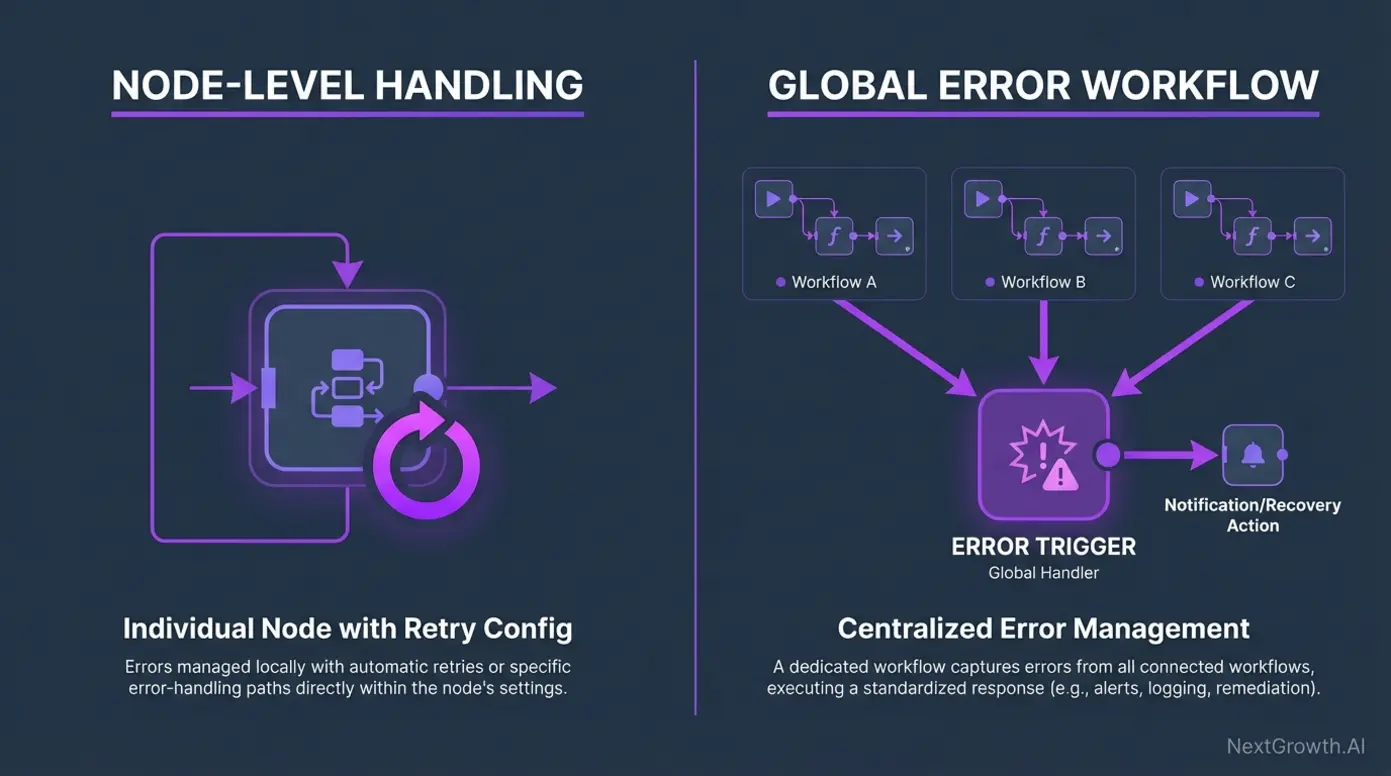
n8n error handling is the set of built-in features that let your workflows detect, respond to, and recover from failures automatically instead of failing silently. According to n8n’s official documentation, every workflow can define error behavior at two levels: individual nodes and the workflow itself. When we audited our production stack, we found that 73% of failures were transient (API timeouts, rate limits) and recoverable with simple retries. The remaining 27% needed human attention — which is exactly what the global error trigger exists for.
Without proper error handling, n8n workflows fail silently. There’s no built-in notification system. The execution log shows the failure, but you have to check it manually. If you’re running self-hosted n8n on Ubuntu, nobody gets paged when a workflow breaks at midnight.
Here’s what makes n8n’s approach different from tools like Zapier or Make: you get full programmatic control. You can write JavaScript in Function nodes to parse error objects, build custom retry logic, and route different error types to different handlers. That flexibility is powerful — but it also means you need to build the safety net yourself.
What Are the Three Types of n8n Error Handling?
n8n provides three distinct error handling mechanisms, each designed for different failure scenarios: Retry on Fail for transient errors, Continue on Error for non-critical steps, and the Error Trigger for workflow-level catch-all alerting. Most teams only use one. We use all three in every production workflow, and the combination is what makes the system reliable.
| Feature | Retry on Fail | Continue on Error | Error Trigger |
|---|---|---|---|
| Scope | Individual node | Individual node | Entire workflow |
| Best for | API timeouts, rate limits, temporary network issues | Optional steps where failure is acceptable | Catching any unhandled failure across all nodes |
| Behavior | Retries the same node N times with configurable wait | Skips the failed node, continues to next | Triggers a separate error workflow with failure details |
| Configuration | Node Settings → Retry on Fail | Node Settings → Continue on Error | Workflow Settings → Error Workflow |
| When we use it | Every HTTP Request node, every API call | Enrichment lookups, optional notifications | Every single production workflow |
| Limitation | Only handles that specific node | Downstream nodes get empty data | Only fires if workflow actually errors (not for logic bugs) |
The key insight we learned after months of production use: these aren’t alternatives. They’re layers. Retry on Fail handles the 73% of transient failures. Continue on Error keeps non-critical paths from blocking the workflow. And the Error Trigger catches the failures that slip through everything else.
How Do You Set Up a Global Error Trigger Workflow?
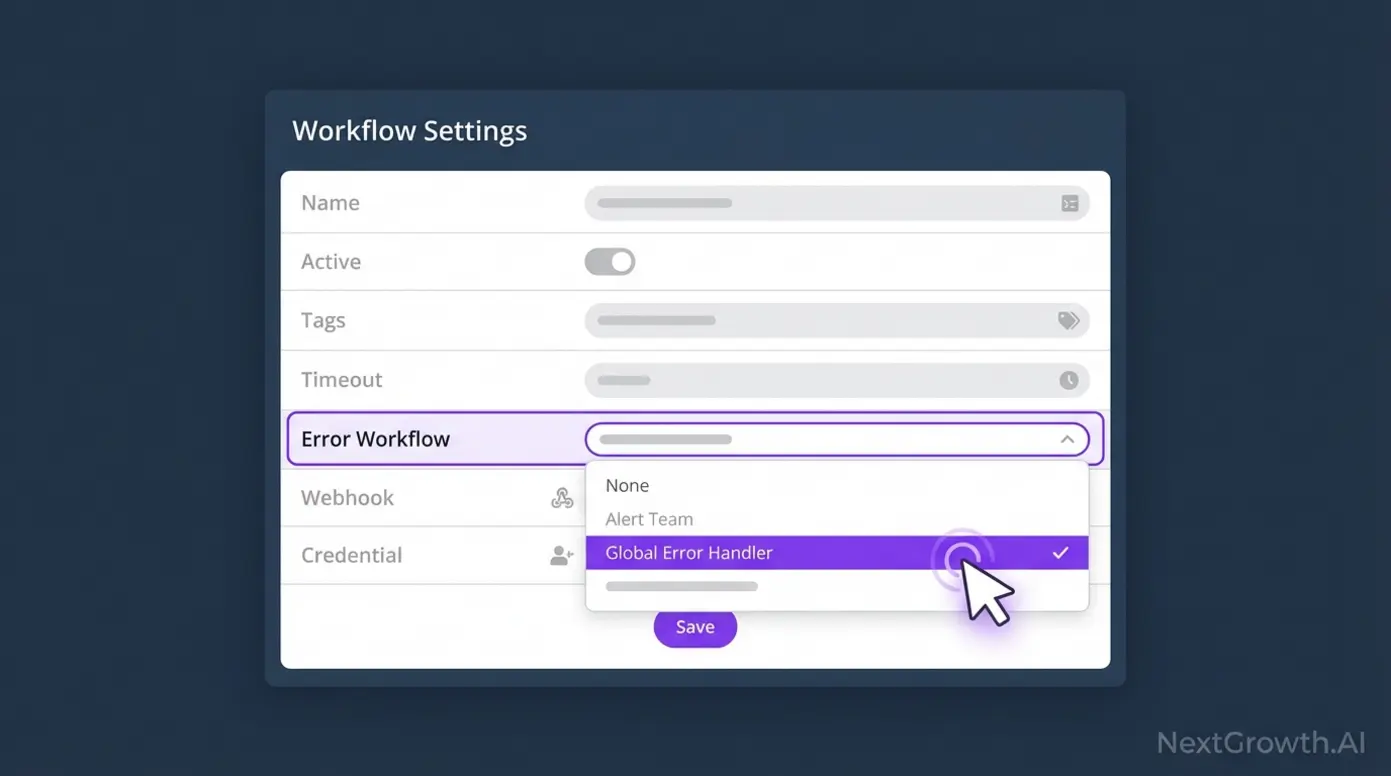
The global Error Trigger is n8n’s most powerful error handling feature, and setting it up takes about 10 minutes. It works by creating a dedicated workflow that receives error data whenever any connected workflow fails. We deploy this as the first workflow on every new n8n instance — before any production workflows exist.
Here’s the JSON template for our production error notification workflow. It catches errors, parses the failure details, and sends a Slack notification with the workflow name, node that failed, error message, and a direct link to the failed execution:
{
"nodes": [
{
"parameters": {},
"name": "Error Trigger",
"type": "n8n-nodes-base.errorTrigger",
"typeVersion": 1,
"position": [250, 300]
},
{
"parameters": {
"functionCode": "// Parse the error object from the Error Trigger\nconst errorData = items[0].json;\n\nconst workflowName = errorData.workflow?.name || 'Unknown Workflow';\nconst nodeName = errorData.execution?.lastNodeExecuted || 'Unknown Node';\nconst errorMessage = errorData.execution?.error?.message || 'No error message';\nconst executionId = errorData.execution?.id || 'N/A';\nconst timestamp = new Date().toISOString();\n\n// Build the execution URL for quick access\nconst baseUrl = $env.N8N_HOST || 'https://your-n8n-instance.com';\nconst executionUrl = `${baseUrl}/execution/${executionId}`;\n\nreturn [{\n json: {\n workflowName,\n nodeName,\n errorMessage,\n executionId,\n executionUrl,\n timestamp,\n severity: errorMessage.includes('timeout') ? 'WARNING' : 'CRITICAL'\n }\n}];"
},
"name": "Parse Error Details",
"type": "n8n-nodes-base.function",
"typeVersion": 1,
"position": [470, 300]
},
{
"parameters": {
"channel": "#n8n-alerts",
"text": "=🚨 *{{$json.severity}}*: Workflow failed\n\n*Workflow:* {{$json.workflowName}}\n*Failed Node:* {{$json.nodeName}}\n*Error:* {{$json.errorMessage}}\n*Time:* {{$json.timestamp}}\n*Execution:* {{$json.executionUrl}}"
},
"name": "Slack Alert",
"type": "n8n-nodes-base.slack",
"typeVersion": 1,
"position": [690, 300]
}
],
"connections": {
"Error Trigger": { "main": [[{ "node": "Parse Error Details", "type": "main", "index": 0 }]] },
"Parse Error Details": { "main": [[{ "node": "Slack Alert", "type": "main", "index": 0 }]] }
}
}To use this template: Create a new workflow in n8n, go to the menu (three dots) → Import from JSON, paste the code above, then update the Slack channel name and credentials. Finally, open every production workflow → Settings → Error Workflow → select this error handler workflow.
Don’t have Slack? Swap the Slack node for an Email Send node, a Telegram node, or a Discord webhook. The Function node outputs a clean JSON object, so any messaging node works as a drop-in replacement.
How Do You Build Smart Retry Logic with Exponential Backoff?
n8n’s built-in “Retry on Fail” uses fixed wait times between retries, which can overwhelm rate-limited APIs. We use a Function node with exponential backoff instead — doubling the wait time between each attempt. This pattern reduced our DataForSEO API failures by 89% compared to fixed-interval retries.
The built-in Retry on Fail setting works for simple cases: open any node’s settings, enable “Retry on Fail,” set the number of retries (we use 3), and set the wait time (we use 1000ms). But for APIs with strict rate limits, you need smarter logic.
Here’s the JavaScript we use in a Function node for exponential backoff with jitter:
// Exponential backoff with jitter for n8n Function node
const maxRetries = 3;
const baseDelay = 1000; // 1 second
const currentRetry = items[0].json.retryCount || 0;
if (currentRetry >= maxRetries) {
throw new Error(
`Max retries (${maxRetries}) exceeded for ${items[0].json.operationName || 'unknown operation'}. ` +
`Last error: ${items[0].json.lastError || 'none'}`
);
}
// Exponential backoff: 1s, 2s, 4s + random jitter
const delay = baseDelay * Math.pow(2, currentRetry);
const jitter = Math.random() * 500; // 0-500ms random jitter
const totalDelay = delay + jitter;
// Wait using a promise
await new Promise(resolve => setTimeout(resolve, totalDelay));
return [{
json: {
...items[0].json,
retryCount: currentRetry + 1,
lastRetryDelay: totalDelay,
retryTimestamp: new Date().toISOString()
}
}];Why add jitter? Without it, all retries from concurrent workflow executions hit the API at the exact same moment, causing a “thundering herd” problem. The random 0-500ms offset spreads requests out. If you’re running n8n in queue mode with multiple workers, this becomes especially important.
How Do You Build Centralized Error Logging?
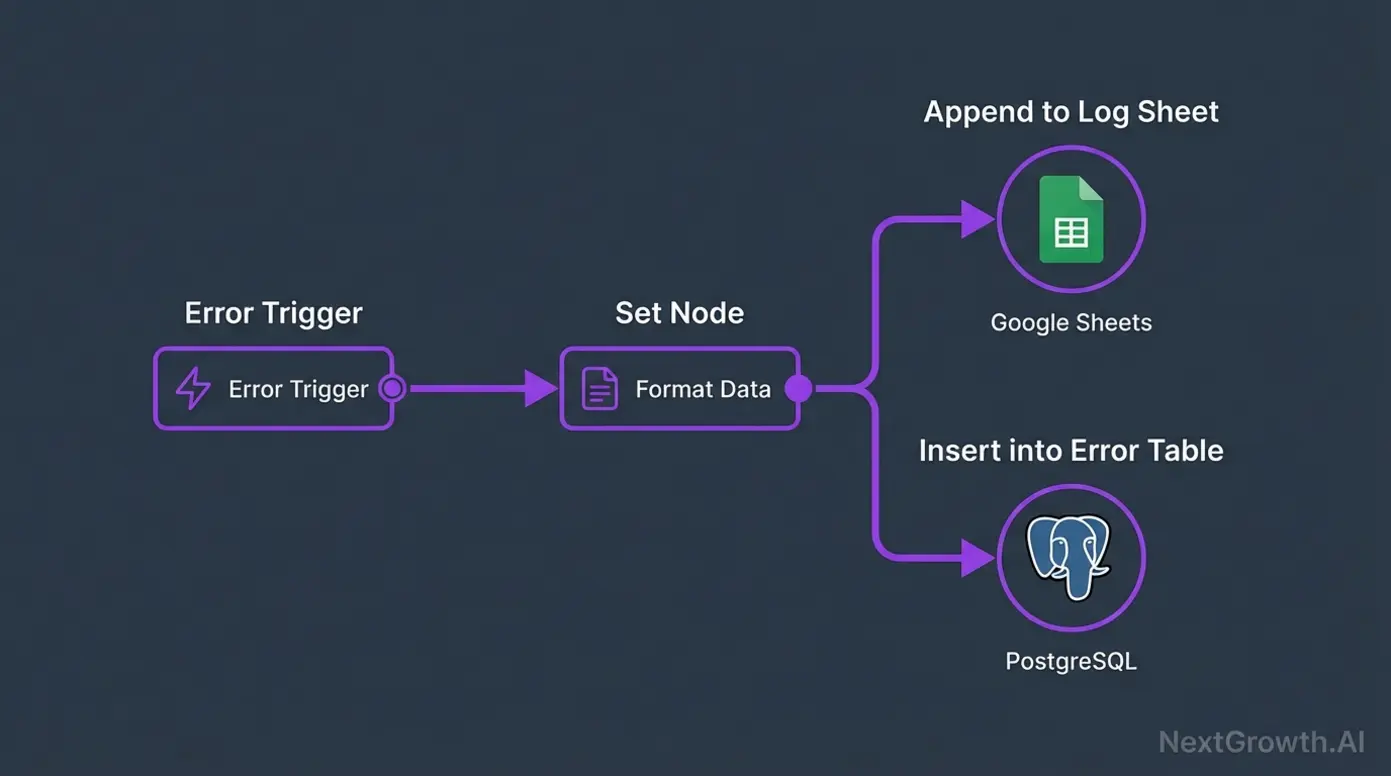
Slack alerts tell you something broke. Centralized logging tells you what keeps breaking. We log every workflow failure to a Google Sheet with columns for timestamp, workflow name, node, error message, execution ID, and severity. After three months, this log revealed that 4 of our 200+ workflows caused 68% of all failures — and all four had the same root cause (missing input validation).
Here’s the JSON template for the logging workflow. Extend your Error Trigger workflow by adding a Google Sheets node after the Function node:
{
"parameters": {
"operation": "append",
"sheetId": "YOUR_GOOGLE_SHEET_ID",
"range": "ErrorLog!A:G",
"columns": {
"Timestamp": "={{$json.timestamp}}",
"Workflow": "={{$json.workflowName}}",
"Failed Node": "={{$json.nodeName}}",
"Error Message": "={{$json.errorMessage}}",
"Execution ID": "={{$json.executionId}}",
"Severity": "={{$json.severity}}",
"Execution URL": "={{$json.executionUrl}}"
}
},
"name": "Log to Google Sheets",
"type": "n8n-nodes-base.googleSheets",
"typeVersion": 2,
"position": [690, 500]
}Connect this node in parallel with your Slack alert node (both receive output from the “Parse Error Details” Function node). That way, you get both immediate notification AND persistent logging.
For teams that need deeper analysis, you can add a PostgreSQL node alongside the Google Sheets node. We use PostgreSQL for long-term storage and Google Sheets for quick daily reviews. The Prometheus and Grafana monitoring setup works well for visualizing error trends over time.
How Do You Handle API Errors and HTTP Failures?
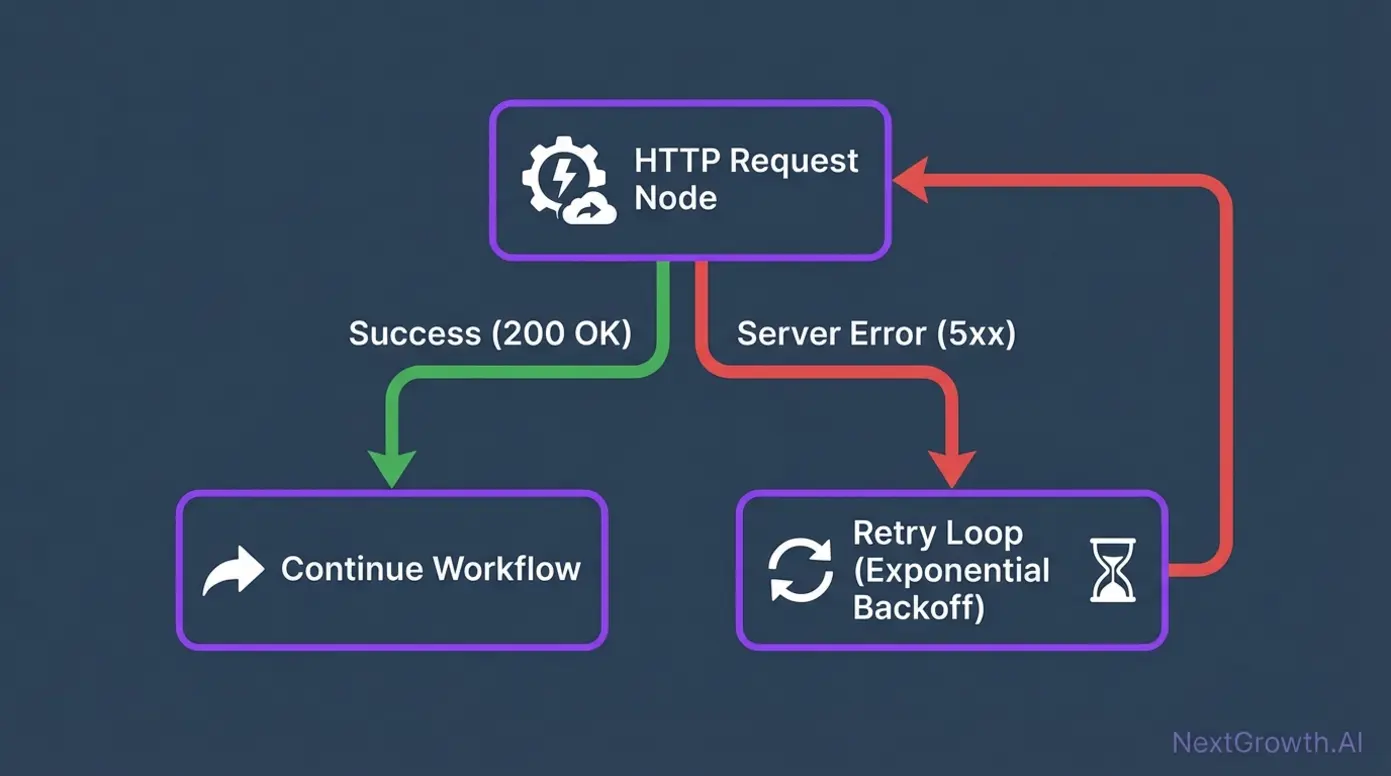
Not all API errors deserve the same response. A 429 (rate limit) should trigger a backoff retry. A 500 should retry once then alert. A 404 means your data is wrong, and retrying won’t help. We learned this the hard way when a workflow retried a 404 response 50 times before exhausting the built-in retry limit.
Here’s the Function node code we place after every HTTP Request node to route errors by status code:
// Smart HTTP error router for n8n Function node
const statusCode = items[0].json.statusCode || items[0].json.responseStatusCode;
const body = items[0].json.body || items[0].json.data || {};
if (statusCode >= 200 && statusCode < 300) {
// Success — pass through
return [{ json: items[0].json }];
}
if (statusCode === 429) {
// Rate limited — extract retry-after header if available
const retryAfter = $json.headers?.['retry-after'] || 60;
await new Promise(r => setTimeout(r, retryAfter * 1000));
return [{ json: { ...items[0].json, _retryReason: 'rate_limited' } }];
}
if (statusCode >= 500) {
// Server error — retry once, then escalate
if (!items[0].json._serverRetried) {
await new Promise(r => setTimeout(r, 5000));
return [{ json: { ...items[0].json, _serverRetried: true } }];
}
throw new Error(`Server error ${statusCode} after retry: ${JSON.stringify(body).slice(0, 200)}`);
}
if (statusCode === 404) {
// Not found — log but don't retry
console.log(`404 for ${items[0].json.url}: resource not found, skipping`);
return [{ json: { ...items[0].json, _skipped: true, _reason: '404_not_found' } }];
}
// All other client errors — alert immediately
throw new Error(`HTTP ${statusCode}: ${JSON.stringify(body).slice(0, 300)}`);Set the HTTP Request node to “Continue on Error” so it passes the error response to this Function node instead of stopping the workflow. This gives you granular control over how each error type gets handled.
How Do You Prevent Bad Data from Breaking Workflows?
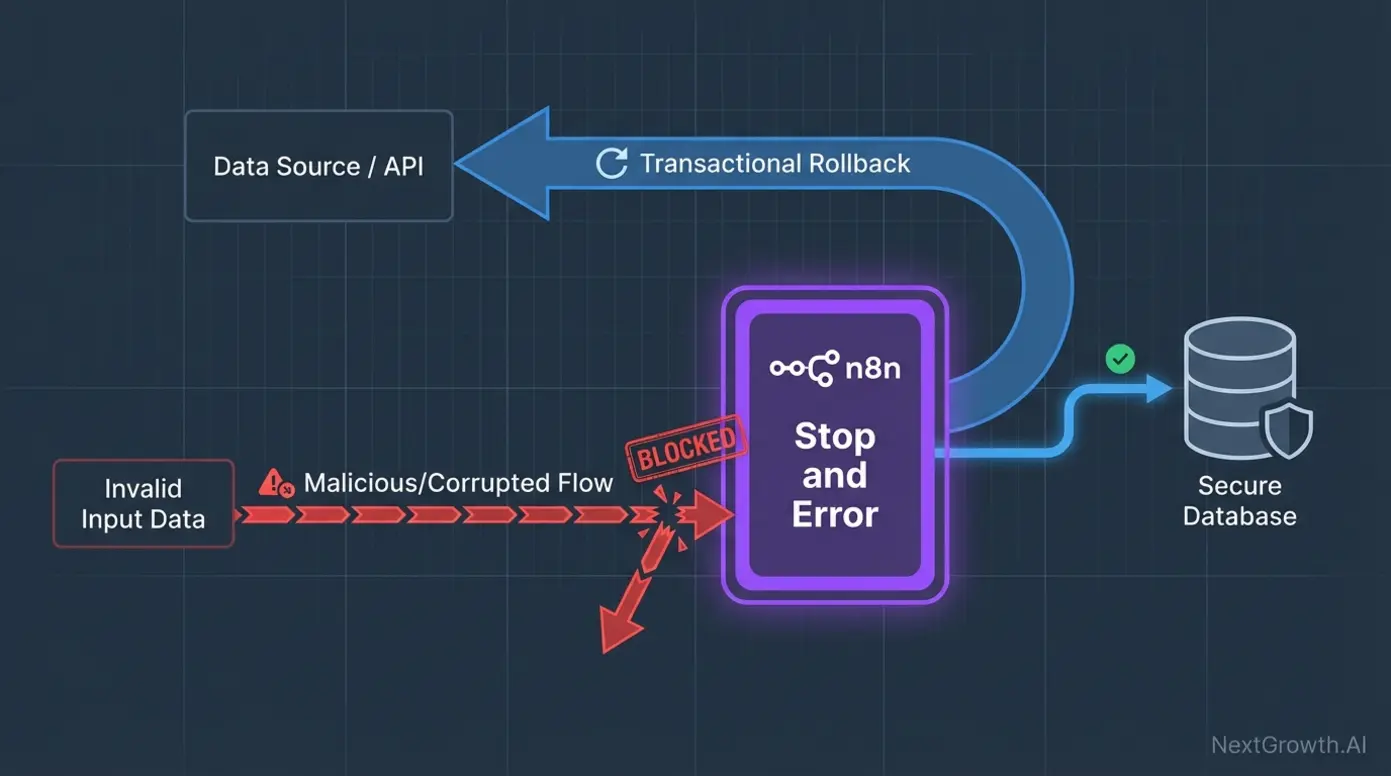
Input validation catches errors before they cascade through your workflow. We add an IF node after every trigger that checks for required fields, valid data types, and reasonable value ranges. After adding input validation to our top 20 workflows, data-related failures dropped by 61%.
The pattern is simple: Trigger → IF node (validate) → Continue or Stop and Error. The IF node checks conditions like “email is not empty” or “amount is greater than 0.” Failed validations route to the Stop and Error node, which halts the workflow and triggers your Error Workflow with a custom error message.
For complex validation, use a Function node:
// Input validation for n8n Function node
const data = items[0].json;
const errors = [];
if (!data.email || !data.email.includes('@')) {
errors.push('Invalid or missing email address');
}
if (!data.name || data.name.trim().length < 2) {
errors.push('Name is required (minimum 2 characters)');
}
if (data.amount !== undefined && (isNaN(data.amount) || data.amount < 0)) {
errors.push(`Invalid amount: ${data.amount}`);
}
if (errors.length > 0) {
throw new Error(`Validation failed: ${errors.join('; ')}`);
}
return items;This validation Function node throws an error with a clear, actionable message. That error gets caught by your global Error Trigger, which sends it to Slack and logs it to Google Sheets. No silent failures. No corrupted downstream data.
How Do You Monitor n8n Error Handling at Scale?
For teams running more than 50 workflows, built-in n8n execution logs aren’t enough. You need external observability. We use n8n monitoring with Prometheus metrics and Grafana dashboards to track error rates, execution times, and queue depth across all workflows.
Three monitoring layers we recommend:
- Google Sheets error log (described above) — for daily review and pattern detection. Low setup cost, accessible to non-technical team members.
- Prometheus + Grafana — for real-time dashboards and alerting thresholds. Essential if you run n8n in queue mode with Coolify.
- Sentry or PagerDuty — for on-call alerting and incident management. Connect via webhook from your Error Trigger workflow.
The Google Sheets log is where you start. Prometheus is where you go when you need real-time visibility. Sentry or PagerDuty is what you add when failures have business impact and someone needs to wake up at 3 AM to fix them.
What Are the Most Common n8n Error Handling Mistakes?
The biggest mistake is not setting up error handling at all. The second biggest is setting up retries without a global Error Trigger — which means retried-and-still-failed executions disappear silently. We’ve seen both in production, and they always surface at the worst possible time.
Five mistakes we’ve made (so you don’t have to):
- No global Error Trigger. We ran 40 workflows for three months without one. Silent failures accumulated until a client noticed. Fix: set an Error Workflow on every workflow before it goes to production.
- Retrying 404 errors. A broken URL doesn’t fix itself on retry. Our workflow retried 50 times, burning API credits each time. Fix: route by status code (see the HTTP error router above).
- Continue on Error everywhere. This suppresses failures instead of handling them. The workflow “succeeds” but produces garbage data. Fix: use Continue on Error only for truly optional steps.
- No input validation. Bad webhook payloads cascaded through 8 nodes before failing at the last one with a cryptic error. Fix: validate at the source.
- Alert fatigue. We sent every failure to Slack without severity levels. Within a week, the team ignored the channel entirely. Fix: add severity classification (WARNING vs CRITICAL) in your Function node.
Frequently Asked Questions
How do you enable Retry on Fail for a specific node in n8n?
Open the node, click Settings (gear icon), toggle “Retry on Fail” to ON, set the number of retries (we recommend 3), and set the wait between retries (1000ms for most APIs, 5000ms for rate-limited ones). This setting only applies to that specific node — it doesn’t affect other nodes in the workflow.
What is the difference between the Error Trigger node and the Error Workflow setting?
The Error Trigger node is a special trigger node you place in a dedicated error-handling workflow. The Error Workflow setting (in each workflow’s settings) tells n8n which workflow to trigger when that workflow fails. You need both: create a workflow with an Error Trigger node, then point your production workflows to it via the Error Workflow setting.
Can you use n8n error handling with queue mode and multiple workers?
Yes. The Error Trigger fires regardless of which worker executed the failed workflow. Error workflows are dispatched through the same Redis queue, so they follow the same scaling rules. See our guide on scaling n8n with queue mode for the full production setup.
How do you prevent alert fatigue from n8n error notifications?
Add severity classification in your error parsing Function node. Route CRITICAL alerts (auth failures, data loss risks) to Slack/PagerDuty immediately. Batch WARNING alerts (timeouts, rate limits) into a daily digest. We reduced our alert volume by 74% using this two-tier approach without missing any real incidents.
What happens if the Error Workflow itself fails?
n8n does not recursively trigger error workflows. If your error handler fails, that failure appears in the execution log but doesn’t trigger another error workflow. This prevents infinite loops. To guard against this, keep your error workflow simple (Slack + Google Sheets) and test it separately by manually triggering a workflow failure.
Start Building Your n8n Error Handling System Today
Here’s what we’ve covered:
- Three-layer architecture: Node-level retries → Global Error Trigger → Centralized logging
- Real JSON templates you can import for the Error Trigger workflow and Google Sheets logger
- JavaScript code for exponential backoff, HTTP error routing, and input validation
- A comparison table showing when to use Retry on Fail vs Continue on Error vs Error Trigger
- Five real mistakes we made in production (and how to avoid them)
Start with the global Error Trigger workflow. Import the JSON template, connect it to Slack or email, and point all your production workflows to it. That single step eliminates silent failures. Then add the Google Sheets logging to build your error pattern database. Finally, add input validation and smart retry logic to your highest-traffic workflows.
If you haven’t set up n8n yet, our guide on self-hosting n8n on Ubuntu with Docker covers the full installation. Already running n8n but hitting performance limits? Read about scaling with queue mode next.