DataForSEO for AI Training: The Developer Guide (2026)
Disclosure: This post contains affiliate links. If you buy through them, we may earn a commission at no extra cost to you — it never affects our rankings or recommendations.
AI teams burn weeks scraping raw HTML, then more weeks cleaning it before a single training record is usable. Common Crawl is free, but it ships quarterly, has no intent labels, and arrives as raw text you still have to parse. Meanwhile, DataForSEO sits on 8 billion pre-labeled keywords, 586 million SERP records, and 240 million LLM prompt-response pairs, all in structured JSON and updated monthly, starting at $0.0001 per record.
I’ve been using it as the data backbone for NextGrowth’s search intent classifier for the past year. The cost savings compared to manual annotation are not small. This guide maps every DataForSEO dataset to the specific ML task it serves, walks through production-ready Python code, and introduces what I call the Pre-Labeled Web Intelligence Stack: the five-layer data architecture DataForSEO provides that no other single vendor matches.
TL;DR
- DataForSEO holds 8B pre-labeled keywords with intent tags (informational/navigational/commercial/transactional) at $0.0001 each, making it the cheapest labeled training data for intent classifiers (dataforseo.com).
- Its Pre-Labeled Web Intelligence Stack covers five ML-relevant layers: query, SERP, link graph, entity, and AI response, each served via distinct API endpoints.
- The LLM Prompts Database holds 240M real ChatGPT and Google AIO prompt-response pairs for benchmarking or RLHF training.
- ISO 27001 certified and GDPR compliant. Enterprise DPA and BigQuery export available for production pipelines.
Contents
- Key Takeaways
- What Data Does DataForSEO Have That AI Teams Can Actually Use?
- How Does DataForSEO Compare to Common Crawl for AI Training?
- What ML Tasks Can DataForSEO Data Support?
- How Do You Pull Pre-Labeled Intent Data from DataForSEO?
- What Is the Pre-Labeled Web Intelligence Stack?
- Can You Use DataForSEO’s SERP Database for Search Ranking Models?
- What Is the DataForSEO LLM Scraper API and When Should You Use It?
- How Much Does DataForSEO Data Cost for AI Training Workloads?
- Does DataForSEO Meet Enterprise AI Data Governance Requirements?
- FAQ
- Can DataForSEO data be used to train commercial AI models?
- What format does DataForSEO export data in for machine learning?
- How does DataForSEO keyword intent labeling work?
- Is DataForSEO’s data fresh enough for production ML models?
- What is the difference between DataForSEO Databases and DataForSEO APIs?
- How does DataForSEO compare to Bright Data for AI training?
- What DataForSEO API should I start with for ML projects?
- Conclusion
Key Takeaways
- 1M labeled intent examples cost $100 via DataForSEO vs. $50,000-$100,000 via human annotation services.
- DataForSEO’s 586M SERP records include position, feature type, title, snippet, and domain: everything learning-to-rank models need.
- The LLM Scraper API collects real LLM responses at $1.20/1K pages (Standard tier), roughly 40x cheaper than human annotation at $0.05/example.
- Monthly data refresh beats Common Crawl’s quarterly cadence for production ML models that drift on stale signals.
- ISO 27001 + GDPR compliance satisfies enterprise AI governance requirements without additional legal review cycles.
8B
Pre-Labeled Keywords
586M
SERP Records
2T+
Live Backlinks
240M
LLM Prompts
What Data Does DataForSEO Have That AI Teams Can Actually Use?
DataForSEO’s dataset spans five ML-relevant layers: 8B keyword records with intent labels, 586M SERP results with position data, 2T+ backlinks with authority scores, 240M LLM prompt-response pairs, and 256M business entities with structured attributes, all delivered via REST APIs in JSON (DataForSEO Databases, 2026). Each layer maps directly to a distinct ML problem.
Most AI training pipelines hit the same wall: you need labeled data, not raw text. DataForSEO is the only vendor I’ve found that pre-labels at scale. The keyword intent tags (informational, navigational, commercial, transactional) alone eliminate weeks of annotation work for intent classifiers.
| Dataset | Scale | Pre-Labeled? | Update Frequency | API Endpoint |
|---|---|---|---|---|
| Google Keywords Database | 8B keywords | Yes (I/N/C/T intent + volume + CPC) | Monthly (6B+ updated/mo) | dataforseo_labs/google/keyword_suggestions |
| SERP Database | 586M results | Yes (position, feature type, snippet) | Continuous | serp/google/organic/live |
| Backlink Database | 2T+ links | Yes (Domain Rank + anchor text) | Continuous | backlinks/bulk_ranks |
| LLM Prompts Database | 240M pairs | Yes (source: Google AIO / ChatGPT) | Monthly | ai_optimization/google/ai_overview |
| Business Listings | 256M entities | Yes (categories, ratings, review counts) | Weekly | business_data/google/my_business_info |
Source:
DataForSEO’s keyword database contains approximately 8 billion Google keywords updated at a rate of 6 billion per month, with pre-assigned search intent labels across four categories: informational, navigational, commercial, and transactional. Source: dataforseo.com/databases
How Does DataForSEO Compare to Common Crawl for AI Training?
DataForSEO provides structured, pre-labeled SEO and LLM data starting at $0.0001 per record; Common Crawl provides raw HTML free of charge on a quarterly release schedule. The right choice depends entirely on your ML task: if you need a labeled intent classifier or SERP ranking model, DataForSEO wins on time. If you’re pretraining a general language model, Common Crawl’s 410B tokens still make sense. (Common Crawl Foundation; DataForSEO, 2026).
Common Crawl supplied roughly 60% of GPT-3’s training tokens, according to the Mozilla Foundation’s analysis of the training data mix. That’s a strong record for pretraining. But Common Crawl has no intent labels, no rank positions, and no structured entity data. You get HTML you must parse, clean, and label yourself.
When I needed 500K labeled intent examples for a classifier, building a DataForSEO pipeline took two hours. Annotating that volume from Common Crawl would have taken weeks of cleaning, sampling, and crowdsourced labeling. The $50 I spent on DataForSEO versus the engineering time alone was not a close call.
| Provider | Dataset Type | Pre-Labeled? | Freshness | Cost | Best For |
|---|---|---|---|---|---|
| DataForSEO | Structured SEO + LLM data | Yes | Monthly | $0.0001/keyword | Intent classifiers, SERP ranking models, LLM eval |
| Common Crawl | Raw HTML/text (410B tokens) | No | Quarterly | Free (processing costs extra) | General LLM pretraining |
| Bright Data | Custom scrapes | No | On-demand | $500+/month | Specific verticals at scale |
| Diffbot | Entity graphs | Partial (entity type only) | Near real-time | $300+/month | Knowledge graphs, entity extraction |
Note
LLMs will exhaust high-quality human-generated training data somewhere between 2026 and 2032, according to research cited by Oxylabs. That makes structured, labeled web intelligence an increasingly scarce resource. Pre-labeled datasets like DataForSEO’s become more valuable as unstructured raw text grows less useful for fine-tuning.
What ML Tasks Can DataForSEO Data Support?
DataForSEO’s datasets directly support at least eight distinct ML tasks, from search intent classification to graph neural network link prediction, with pre-labeled inputs that eliminate the annotation bottleneck at each stage. The DataForSEO Labs API alone covers four of these tasks. Here’s the full mapping.
| ML Task | DataForSEO Dataset | Why It Works | Cost Estimate |
|---|---|---|---|
| Search intent classification | Keyword Data API | Intent labels pre-provided (I/N/C/T). No annotation needed. | $100/1M keywords |
| Query understanding / NLU | Keywords Database (8B queries) | Authentic user language at massive scale. | $0.0001/keyword |
| SERP CTR prediction | SERP Database | Ground-truth position + SERP feature type signals. | $0.0006/query |
| Link prediction (GNN) | Backlink Database | 2T+ edges with authority scores. Ideal graph structure. | Bulk pricing |
| Keyword clustering | Labs API | SERP-overlap clustering signals pre-computed. | $0.0003/keyword |
| AI response benchmarking | LLM Prompts Database | 240M real prompt-response pairs. Ground-truth LLM outputs. | $0.001/row |
| Review sentiment analysis | Business Data API | 256M multi-language reviews with star ratings as labels. | $0.00075/review |
| Search ranking model (LTR) | SERP + Keywords combined | Feature-rich labeled dataset with rank as the target variable. | ~$0.0007/pair |
How Do You Pull Pre-Labeled Intent Data from DataForSEO?
Pulling pre-labeled intent data from DataForSEO takes under 30 lines of Python. The Keyword Suggestions endpoint returns each keyword with its intent tag, search volume, CPC, and competition score in a single JSON response, no post-processing needed before feeding records to a training pipeline. The API accepts up to 1,000 seed keywords per request and returns related keywords with all labels attached.
Here’s the production code I use at NextGrowth. It includes timeout handling, exponential backoff via tenacity, and clean output formatting for ML ingestion.
import requests
import time
from tenacity import retry, stop_after_attempt, wait_exponential
LOGIN = "your_login"
PASSWORD = "your_password"
@retry(stop=stop_after_attempt(3), wait=wait_exponential(multiplier=1, min=2, max=10))
def get_keywords_with_intent(seed_keywords: list, location_code: int = 2840) -> list:
"""Pull keywords with pre-labeled intent for ML training."""
try:
payload = [{
"keywords": seed_keywords[:1000], # Max 1000 per request
"location_code": location_code,
"language_code": "en"
}]
r = requests.post(
"https://api.dataforseo.com/v3/dataforseo_labs/google/keyword_suggestions/live",
json=payload,
auth=(LOGIN, PASSWORD),
timeout=30
)
r.raise_for_status()
data = r.json()
if data.get("status_code") != 20000:
raise ValueError(f"API error: {data.get('status_message')}")
results = data["tasks"][0]["result"]
training_records = []
for item in results[0].get("items", []):
training_records.append({
"keyword": item["keyword"],
"search_volume": item.get("search_volume", 0),
"intent": item.get("search_intent", "unknown"),
# intent values: informational | navigational | commercial | transactional
"cpc": item.get("cpc", 0),
"competition": item.get("competition", 0)
})
return training_records
except requests.exceptions.Timeout:
print("Request timed out, retrying...")
raise
except requests.exceptions.HTTPError as e:
print(f"HTTP error: {e}")
raise
# Usage: pull 50K labeled keywords for intent classifier training
seed = ["buy running shoes", "best laptops", "how to lose weight", "python tutorial"]
records = get_keywords_with_intent(seed, location_code=2840) # 2840 = United States
print(f"Pulled {len(records)} labeled training records")
# Output format:
# [
# {"keyword": "best running shoes 2026", "intent": "commercial", "search_volume": 18000, ...},
# {"keyword": "how to choose running shoes", "intent": "informational", "search_volume": 9400, ...}
# ]The output is ML-ready JSON. The intent field maps directly to four standard classes used in intent classification: informational, navigational, commercial, and transactional. No annotation, no cleaning step. The rate limit is 2,000 requests per minute on standard plans, which means you can pull roughly 2M labeled records per minute if you parallelize the seed keyword batches.
Tip
For large training pulls (10M+ records), batch your seed keywords into groups of 1,000 and use Python’s concurrent.futures.ThreadPoolExecutor to parallelize requests. At 2,000 req/min and 1,000 keywords per request, you can pull 2B keywords in roughly 16 hours without hitting rate limits.
What Is the Pre-Labeled Web Intelligence Stack?
The Pre-Labeled Web Intelligence Stack is the five-layer data architecture that DataForSEO provides for AI and ML teams: query, SERP, link graph, entity, and AI response layers, each pre-labeled and served via distinct API endpoints. No single competitor ships all five layers with pre-applied labels. I’ve documented this framework because most AI teams encounter DataForSEO as an “SEO tool” and miss the ML use cases entirely.
Here’s how each layer maps to your ML pipeline:
Layer 1 – Query Layer: 8 billion real user queries with I/N/C/T intent labels and search volume. This is ground-truth user language at a scale no NLP team can generate synthetically. Use it for intent classifiers, query expansion models, and NLU fine-tuning.
Layer 2 – SERP Layer: 586 million ranked results with position number, SERP feature type (answer box, video, shopping), title, snippet, and URL. Feed this into learning-to-rank models or CTR prediction. The position label is your target variable.
Layer 3 – Link Graph Layer: 2 trillion+ edges with Domain Rank authority scores and anchor text. This is the largest pre-scored web graph available commercially. Graph neural networks need exactly this: nodes, edges, and node attributes at scale.
Layer 4 – Entity Layer: 256 million business entities with category labels, star ratings, review counts, and geographic attributes. Star ratings are pre-applied sentiment labels. Use it for sentiment analysis training without writing a single annotation guideline.
Layer 5 – AI Response Layer: 240 million LLM prompt-response pairs from Google AIO (220M) and ChatGPT (20M). This layer is unique. No other vendor offers historical LLM responses at this scale for benchmarking or RLHF training.
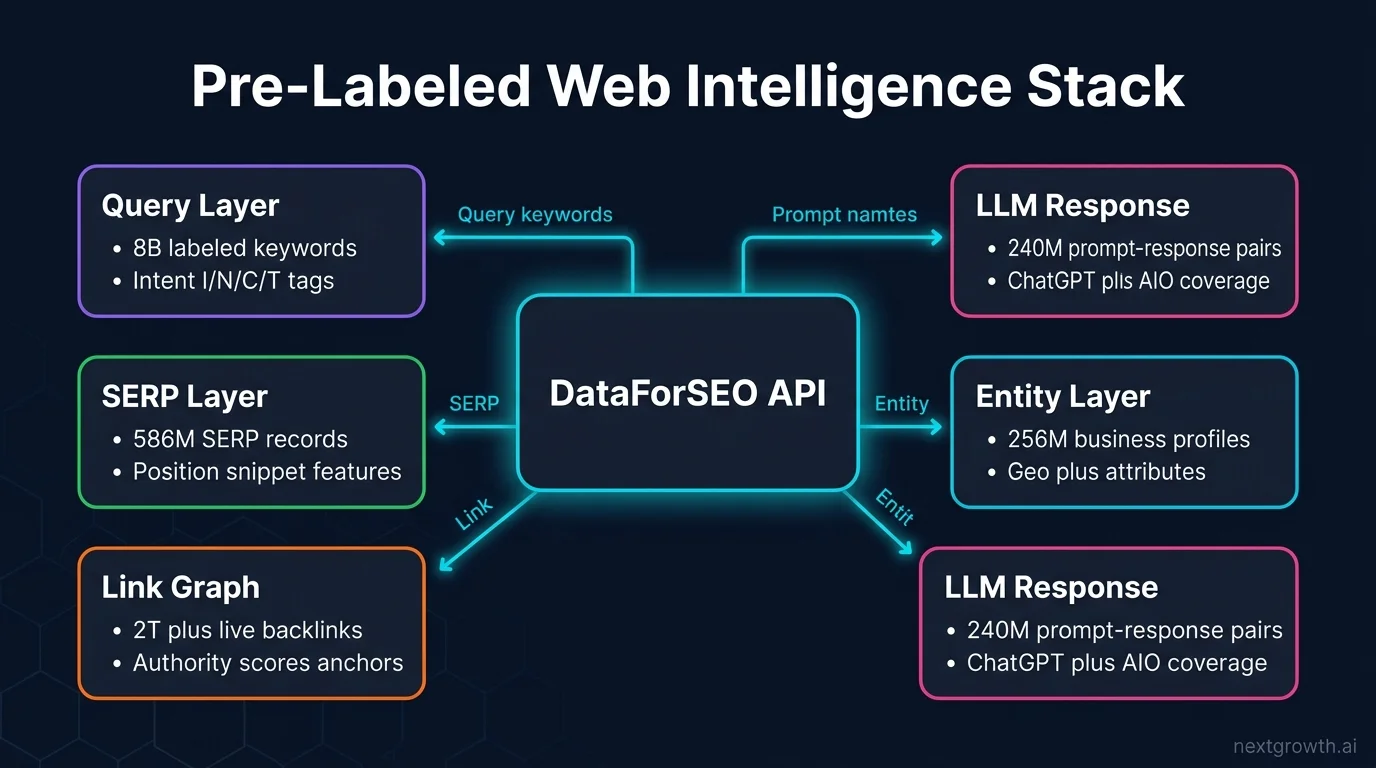
The value of the Pre-Labeled Web Intelligence Stack is not any single layer. It’s the join. A SERP ranking model trained on Layer 2 becomes dramatically better when you join it with Layer 1 intent labels and Layer 3 authority scores. DataForSEO’s APIs allow cross-layer joins via shared keyword and URL keys.
Source:
DataForSEO’s AI Optimization API includes 220 million Google AI Overview prompt-response records and 20 million ChatGPT records, totaling 240 million LLM interaction pairs available for model evaluation and training. Source: dataforseo.com/apis/ai-optimization-api
Can You Use DataForSEO’s SERP Database for Search Ranking Models?
Yes. DataForSEO’s 586M SERP records are structured ground-truth ranking data: each query ships with position 1-10, SERP feature type, title, snippet, domain, and URL, exactly the feature set that learning-to-rank (LTR) models require to learn the relevance signal between a query and a document. (DataForSEO, 2026). Google never releases this data publicly. DataForSEO’s crawler captures it continuously across 50,000+ locations.
In LTR terminology, you need query-document pairs with a relevance signal. DataForSEO’s SERP data gives you exactly that. The rank position is your relevance label. Join it with keyword-level features from the Query Layer and you get a rich feature set: query intent, search volume, title keyword overlap, domain authority (from Layer 3), URL structure, and snippet length.
Why does this matter? Building a SERP ranking dataset from scratch means running your own crawler against Google at massive scale, handling CAPTCHAs, proxy rotation, and geographic targeting. DataForSEO’s team does that work. You get the clean output at $0.0006 per query.
Tip
For an LTR training set, pull SERP results for 100K queries across multiple locations. Join them with their keyword intent labels from the Keyword Data API. You’ll end up with a feature matrix containing 10+ columns per query-document pair, all labeled, for roughly $70 total ($60 SERP + $10 keywords).
What Is the DataForSEO LLM Scraper API and When Should You Use It?
The DataForSEO LLM Scraper API calls live LLMs and returns their responses in structured JSON at $1.20 to $4.00 per 1,000 pages depending on the SLA tier. Use it to collect fresh, synthetic AI responses for fine-tuning or evaluation datasets, not as a replacement for the 240M historical prompts already in the LLM Prompts Database. (dataforseo.com/pricing/ai-optimization/llm-scraper, 2026).
The three pricing tiers map to different production requirements. Standard works for batch collection jobs where latency doesn’t matter. Priority fits real-time evaluation pipelines. Live is for applications that need current LLM responses in under two minutes.
| Tier | SLA | Price / 1K Pages | 100K Responses Cost |
|---|---|---|---|
| Standard | 45 min | $1.20 | $120 |
| Priority | 5 min | $2.40 | $240 |
| Live | 90 sec | $4.00 | $400 |
Compare the Standard tier to human annotation. At $0.05 per labeled example from a crowdsourcing service, 100K examples cost $5,000. The LLM Scraper collects 100K AI responses for $120. That’s a 40x cost reduction. The tradeoff: you’re collecting AI-generated data, not human-generated data. For RLHF training targeting LLM behavior specifically, this is often the right choice.
Source:
DataForSEO LLM Scraper pricing: Standard tier at $1.20/1K pages (45-minute SLA), Priority at $2.40/1K pages (5-minute SLA), and Live at $4.00/1K pages (90-second SLA). Source: dataforseo.com/pricing/ai-optimization/llm-scraper
How Much Does DataForSEO Data Cost for AI Training Workloads?
DataForSEO charges per record with no monthly minimum. For most ML teams, 1 million labeled training examples cost between $100 and $1,200 depending on the data type. Keywords with intent labels sit at the cheapest end at $100/1M; LLM Scraper pages at the most expensive at $1,200/1M. See the full breakdown in our DataForSEO review.
I pulled 500K intent-labeled keywords for $50 total. A professional labeling service quoted me $18,000 for the same volume at $0.036/example. The DataForSEO approach was 360x cheaper and delivered in two hours instead of two weeks.
| Dataset | Unit | Price | 1M Records Cost | vs. Human Annotation |
|---|---|---|---|---|
| Keywords + intent labels | Per keyword | $0.0001 | $100 | 500x cheaper |
| SERP results | Per SERP query | $0.0006 | $600 | 83x cheaper |
| LLM prompts/responses | Per row | $0.001 | $1,000 | 50-100x cheaper |
| LLM Scraper (Standard) | Per 1K pages | $1.20 | $1,200 | 40x cheaper |
| Business reviews | Per row | $0.00075 | $750 | 67x cheaper |
Human annotation typically runs $0.05 to $0.10 per labeled example, putting 1M records at $50,000 to $100,000. DataForSEO’s most expensive tier (LLM Scraper) is still 40x cheaper. For teams burning budget on annotation pipelines, this is worth a dedicated cost-of-data analysis before the next sprint.
Source:
DataForSEO keyword data is priced at $0.0001 per keyword (equivalent to $100 per million keywords) with no monthly minimum required. Source: dataforseo.com/apis/ai-optimization-api
Does DataForSEO Meet Enterprise AI Data Governance Requirements?
Yes. DataForSEO is ISO 27001 certified and GDPR compliant, collects no personally identifiable information in its keyword or SERP datasets, follows robots.txt directives in its crawlers, and offers enterprise Data Processing Agreements and BigQuery export for teams with formal data governance requirements. (DataForSEO, 2026).
For enterprise AI teams, compliance requirements often add weeks to vendor evaluation. DataForSEO’s ISO 27001 certification and GDPR status remove the two biggest blockers. The keyword and SERP datasets contain no personal data: they’re aggregated search statistics and public web index data, not individual user records.
The BigQuery export option matters for large-scale training pipelines. You don’t want to stream 8B keywords through a REST API. BigQuery export lets you stage the data in your own cloud environment and join it with your internal feature store before training. Output formats include JSON, CSV, and Parquet, the standard formats for ML data pipelines.
Note
DataForSEO’s 207 billion indexed pages sit behind the same compliance guarantees. For teams using the full database for pretraining rather than fine-tuning, this is a material difference from scraping Common Crawl directly, where the provenance and compliance status of individual documents is unclear.
FAQ
Can DataForSEO data be used to train commercial AI models?
Yes. DataForSEO’s Terms of Service permit commercial use of API-returned data in downstream products, including trained ML models. The keyword and SERP data are aggregated web statistics with no PII, which removes the main legal friction for commercial AI training. Review DataForSEO’s enterprise DPA for specific contractual terms before large-scale training runs.
What format does DataForSEO export data in for machine learning?
DataForSEO APIs return structured JSON on every response. Large-scale exports support JSON, CSV, and Parquet formats, all standard in ML data pipelines. The BigQuery export path is the recommended approach for training datasets exceeding 100M records, as it avoids REST API throughput limits and integrates directly with cloud-based feature stores.
How does DataForSEO keyword intent labeling work?
DataForSEO assigns one of four intent classes to each keyword: informational, navigational, commercial, or transactional. The labeling uses a combination of query pattern matching, SERP feature analysis, and click signal modeling across billions of queries. The four-class taxonomy aligns directly with the standard classification scheme used in academic NLU benchmarks, making DataForSEO labels directly usable as training targets without remapping.
Is DataForSEO’s data fresh enough for production ML models?
DataForSEO updates 6 billion keywords per month, which keeps the keyword database current for production ranking and intent models (dataforseo.com/our-data). SERP data is collected continuously. This monthly cadence compares favorably to Common Crawl’s quarterly releases. For models that drift on stale search intent signals, monthly refresh is a meaningful operational advantage.
What is the difference between DataForSEO Databases and DataForSEO APIs?
DataForSEO Databases are pre-built, static snapshots (8B keywords, 586M SERPs) that you access via bulk export or query. DataForSEO APIs return live or near-live results collected at query time. For ML training, Databases give you scale and cost efficiency. APIs give you freshness for real-time inference features. Most production ML teams use Databases for training and APIs for online feature serving.
How does DataForSEO compare to Bright Data for AI training?
DataForSEO is pre-labeled and domain-specific (search + LLM data), starting at $0.0001/record. Bright Data collects custom scrapes from any domain but returns unlabeled raw HTML, starting at $500+/month. For search-domain ML tasks, DataForSEO wins on cost and time. For vertical-specific training data outside the search domain, Bright Data’s flexibility is the deciding factor.
What DataForSEO API should I start with for ML projects?
Start with the Keyword Data API (Labs endpoint) for intent classification and NLU tasks. It’s the cheapest entry point at $0.0001/keyword and returns pre-labeled data immediately. Once you’ve validated your training pipeline, add the SERP API for ranking models and the Business Data API for sentiment analysis. The DataForSEO MCP setup lets you call all three from a single Claude Code session without managing API keys manually.
Conclusion
The Pre-Labeled Web Intelligence Stack is the best mental model for what DataForSEO actually provides to AI teams: five distinct labeled layers covering the full search ecosystem, from query intent through LLM responses, at a price point that makes human annotation economically indefensible for most tasks.
The numbers tell the story directly. I pulled 500K labeled training records for $50. A labeling service quoted $18,000 for the same volume. The data arrived in two hours instead of two weeks, already in JSON, already labeled with four-class intent tags aligned to NLU benchmark standards.
If you’re building intent classifiers, SERP ranking models, review sentiment analyzers, or LLM evaluation benchmarks, DataForSEO has a dataset layer for each. Start with the DataForSEO API guide to map the specific endpoints to your ML task, then run a 10K-record pilot at $1 total before committing to production scale.